알고리즘/알고리즘
알고리즘 - 정렬
- -
💡 이 게시글에선 기본 정렬 알고리즘에 대해 다룰 것 입니다.
시간 복잡도 O(n²)
정렬 시간이 정렬할 자료의 제곱에 비례해서 늘어납니다. 이러한 이유로 잘 사용되지 않는 정렬 방식들 입니다.
버블 정렬 (Bubble Sort)

1번째와 2번째 원소를 비교하여 정렬하고, 2번째와 3번째, ..., n-1번째와 n번째를 정렬한 뒤 다시 처음으로 돌아가 반복하는 방식으로 두 개의 인접한 요소를 비교하며 정렬하는 것을 버블 정렬이라고 합니다.
쉽게 구현할 수 있지만 시간복잡도가 O(N^2)이기 때문에 잘 사용되지 않습니다.
동일 값에 대한 원래 순서를 보장하는 안정(Stable) 정렬입니다.
public class Bubble {
public static void sort(int[] arr) {
for (int i = 1; i < arr.length; i++) {
for (int j = 0; j < arr.length - i; j++) {
if (arr[j] > arr[j + 1]) {
int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
}
}
}
}
}
선택 정렬 (Selection Sort)
배열을 순회하면서 가장 작은 값을 앞부터 채워나가는 방식을 선택 정렬이라고 합니다.
시간 복잡도는 O(N^2)으로 버블 정렬과 같지만, 배열 내에서 교환하는 작업을 훨씬 덜 하기 때문에 버블 정렬보단 빠릅니다.
중복 값에 대한 원래 순서를 보장하는 안정 정렬이 아닙니다.
public class Selection {
public static void sort(int[] arr) {
for (int i = 0; i < arr.length - 1; i++) {
int minIdx = i;
for (int j = i + 1; j < arr.length; j++) {
if (arr[minIdx] > arr[j]) {
minIdx = j;
}
}
int tmp = arr[minIdx];
arr[minIdx] = arr[i];
arr[i] = tmp;
}
}
}
삽입 정렬 (Insertion Sort)

비교하고자 하는 원소를 이전의 원소들과 비교하여 본인보다 작은 값 뒤에(원소들의 사이에) 삽입하고 뒤의 원소들을 한칸씩 밀어내는 정렬을 삽입 정렬이라고 합니다.
시간 복잡도는 O(N^2)지만, 배열이 작은 경우 상당한 효율을 보여주는 정렬입니다. 또한, 이미 정렬된 자료구조에 자료를 하나씩 삽입/제거하는 경우에도 좋습니다. Stable Sor 입니다.
public class Insertion {
public static void sort(int[] arr) {
for(int i = 1; i < arr.length; i++) {
int target = arr[i];
// 기준 원소의 앞의 원소들과 비교
int compareIdx = i - 1;
// 기준 원소 < 비교 원소
while(compareIdx >= 0 && target < arr[compareIdx]) {
arr[compareIdx + 1] = arr[compareIdx]; // 비교 값들을 한칸 씩 미루기
compareIdx--;
}
// 기준 원소 > 비교 원소
arr[compareIdx + 1] = target;
}
}
}
시간 복잡도 O(n log n)
합병 정렬 (Merge Sort)

주어진 리스트를 최대한 분할하여 최대한 작게 쪼개진 시점에 비교하여 정렬한 후, 다시 합치는 방법을 합병 정렬이라고 합니다.
안정 정렬이며 최악의 경우에도 O(nlogn)을 보장합니다.
추가적인 배열로 인해 메모리 사용량이 많고, 원본 배열에 정렬된 값을 복사해 넣는 과정이 많은 시간을 소비하기 때문에 데이터가 많을 경우 시간이 많이 소요됩니다.
public class Merge {
public static void sort(int[] arr) {
/**
* size : 비교할 리스트의 크기, 2의 배수로 증가
* start ~ mid : 왼쪽 리스트
* mid+1 ~ end : 오른쪽 리스트
*/
for (int size = 1; size <= arr.length; size += size) {
for (int j = 0; j < arr.length; j += size * 2) {
int start = j;
int mid = j + size - 1;
int end = Math.min(start + (size * 2) - 1, arr.length - 1);
merge(arr, start, mid, end);
}
}
}
/**
* 왼쪽 리스트와 오른쪽 리스트를 합병
*/
private static void merge(int[] arr, int start, int mid, int end) {
// 합병을 위한 배열 선언
int[] sorted = new int[arr.length];
/**
* left : 왼쪽 리스트 시작 인덱스
* right : 오른쪽 리스트 시작 인덱스
*/
int left = start;
int right = mid + 1;
// 합병을 위한 배열의 삽입 위치를 추적
int idx = left;
// 두 리스트 전부 합병되지 않았을 경우
while (left <= mid && right <= end) {
if (arr[left] <= arr[right]) {
sorted[idx] = arr[left++];
} else {
sorted[idx] = arr[right++];
}
idx++;
}
// 왼쪽은 합병 완료, 오른쪽이 남은 경우
while (right <= end) {
sorted[idx] = arr[right++];
idx++;
}
// 오른쪽은 합병 완료, 왼쪽이 남은 경우
while (left <= mid) {
sorted[idx] = arr[left++];
idx++;
}
// 원래 배열에 합병 배열을 복사
for (int i = start; i <= end; i++) {
arr[i] = sorted[i];
}
}
}
힙 정렬 (Heap Sort)

힙 자료구조를 이용한 정렬을 힙 정렬이라고 합니다.
힙은 가장 큰 값(작은 값)을 꺼낼 수 있는데, 이를 그대로 정렬에 이용하는 것 입니다.
부분 정렬을 할 때 효과적이며, 최악의 경우에도 O(nlogn)을 보장합니다.
다른 O(nlogn) 알고리즘에 비해 성능이 조금 떨어지고, 안정 정렬이 아닙니다.
public class Heap {
public static void sort(int[] arr) {
// 배열 크기가 0,1이면 정렬할 필요가 없음
if (arr.length < 2) {
return;
}
// Max Heap 만들어주기
for (int i = (arr.length - 2) / 2; i >= 0; i--) {
heapify(arr, i, arr.length - 1);
}
/**
* 루트 노드 = 최대 값
* 루트 노드를 마지막 노드와 교환 후, 변경된 루트 노드를 heapify
*/
for (int i = arr.length - 1; i > 0; i--) {
swap(arr, 0, i);
heapify(arr, 0, i - 1);
}
}
private static void heapify(int[] arr, int parent, int end) {
int left;
int right;
int curParent = parent;
int max;
while (true) {
// 자식 노드들
left = curParent * 2 + 1;
right = curParent * 2 + 2;
// 자식 노드 중 가장 큰 값을 가진 노드 인덱스
max = curParent;
if (right <= end) { // 자식노드가 둘일 때
max = arr[left] < arr[right] ? right : left;
} else if (left <= end) { // 자식노드가 하나일 때
max = left;
} else { // 자식노드가 없을 때
break;
}
// 자식 노드의 값이 더 크다면 부모 노드와 swap
if (arr[curParent] < arr[max]) {
swap(arr, curParent, max);
curParent = max; // 변경된 후에도 Heap을 유지시켜야 하니 현재 부모를 자식노드로 변경
} else {
break;
}
}
}
private static void swap(int[] arr, int a, int b) {
int temp = arr[a];
arr[a] = arr[b];
arr[b] = temp;
}
}
퀵 정렬 (Quick sort)

피벗(pivot)이라는 적절한 원소 하나를 기준으로 두 개의 부분 리스트로 나누어 정렬하는 방식입니다.
피벗을 기준으로 왼쪽은 피벗보다 작은 값들의 부분리스트로, 오른쪽은 피벗보다 큰 값들의 부분리스트로 나눈 후, 나누어진 리스트 내에서 피벗을 하나 설정해두고 위의 과정을 반복하여 정렬이 끝날 때 까지 반복합니다.
평균적으로 O(n log n) 정렬 중에 최고의 성능을 보여줍니다. 그러나 피벗을 잘못 선택하면 최악의 경우 O(n^2)까지 나올 수 있기 때문에 적절한 방법을 통해 피벗을 선택하거나 다른 알고리즘과 함께 사용되는 경우가 많습니다.
안정 정렬이 아니고, 재귀를 사용하기 때문에 재귀를 사용하지 못할 경우, 구현이 복잡해집니다.
아래의 구현은 피벗을 맨 왼쪽으로 선택했을 시의 구현입니다. 피벗 선택에 맞춰 수정하시면 됩니다.
public class Quick {
public static void sort(int[] arr) {
recur(arr, 0, arr.length - 1);
}
/**
* 맨 왼쪽 피벗을 기준으로 두 개의 부분 리스트로 나눔(파티셔닝)
* 오른쪽 부터 대소비교 시작해야 안꼬입니다.
*/
private static int partition(int[] arr, int start, int end) {
int left = start;
int right = end;
int pivot = left;
while (left < right) {
while (arr[pivot] < arr[right] && left < right) {
right--;
}
while (arr[left] <= arr[pivot] && left < right) {
left++;
}
swap(arr, left, right);
}
// 피벗과 left와 right가 만난 지점을 교환
swap(arr, pivot, left);
// 피벗 위치 반환
return left;
}
public static void recur(int[] arr, int start, int end) {
if (start >= end) {
return;
}
int pivot = partition(arr, start, end);
// 나누어진 두 부분 리스트를 재귀로 파티셔닝
recur(arr, start, pivot - 1);
recur(arr, pivot + 1, end);
}
private static void swap(int[] arr, int a, int b) {
int tmp = arr[a];
arr[a] = arr[b];
arr[b] = tmp;
}
}
트리 정렬 (Tree Sort)

정렬할 원소들을 이진 탐색 트리로 만들어 중위 순회(In-order)로 정렬하는 방식입니다.
이 방식의 경우, 쉽게 구현할 수 있지만 배열로 구현하려하면 최악의 경우 2^n의 공간 복잡도를 차지하기 때문에 되도록이면 아래와 같이 구현하는 것이 좋습니다.
public class Tree {
public static int idx;
public static void sort(int[] arr) {
Node root = new Node(arr[0]);
for (int i = 1; i < arr.length; i++) {
Node cur = root;
while (true) {
if (cur.value <= arr[i]) {
if (cur.right == null) {
cur.right = new Node(arr[i]);
break;
} else {
cur = cur.right;
}
} else if (cur.value > arr[i]) {
if (cur.left == null) {
cur.left = new Node(arr[i]);
break;
} else {
cur = cur.left;
}
}
}
}
inOrder(arr, root);
}
private static void inOrder(int[] arr, Node parent) {
if (parent == null) {
return;
}
inOrder(arr, parent.left);
arr[idx++] = parent.value;
inOrder(arr, parent.right);
}
private static class Node {
int value;
Node left;
Node right;
public Node(int value) {
this.value = value;
}
}
}
기타 정렬
기수 정렬 (Radix Sort)

기수 정렬은 낮은 자리 수부터 정렬하는 방식입니다.
기수 정렬은 자릿수가 있는 데이터(정수, 문자열 등)에서만 수행이 가능하며, 데이터끼리의 직접적인 비교 없이 정렬을 수행하다 보니 빠릅니다. 시간복잡도는 O(자릿수 * n)입니다.
큐를 이용하여 구현합니다.
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.Queue;
public class Radix {
public static void sort(int[] arr) {
ArrayList<Queue<Integer>> list = new ArrayList<>();
for (int i = 0; i < 10; i++) {
list.add(new LinkedList<>());
}
int idx = 0;
int div = 1;
int maxLen = getMaxLen(arr);
for (int i = 0; i < maxLen; i++) {
for (int j = 0; j < arr.length; j++) {
list.get(arr[j] / div % 10).offer(arr[j]);
}
for (int j = 0; j < 10; j++) {
Queue<Integer> queue = list.get(j);
while (!queue.isEmpty()) {
arr[idx++] = queue.poll();
}
}
idx = 0;
div *= 10;
}
}
// 원소들의 최대 자리수 구하기
public static int getMaxLen(int[] arr) {
int maxLen = 0;
for (int i = 0; i < arr.length; i++) {
int len = (int) Math.log10(arr[i]) + 1;
if(maxLen< len) maxLen = len;
}
return maxLen;
}
}
계수 정렬 (Counting Sort)

데이터의 수를 세고, 그것을 이용해 정렬하는 방식입니다.
보통 정수 자료를 정렬할 때 사용합니다. 주어진 원소들의 최대값이 작으면 작을수록 매우 효율적인 정렬 방식입니다.
import java.util.ArrayList;
import java.util.Collections;
import java.util.HashMap;
public class Counting {
public static void sort(int[] arr) {
// 최대값이 작다면, 배열로 구성하는게 더 유리합니다.
HashMap<Integer, Integer> map = new HashMap<>();
for (int i : arr) {
map.put(i, map.getOrDefault(i, 0) + 1);
}
ArrayList<Integer> list = new ArrayList<>(map.keySet());
Collections.sort(list);
int idx = 0;
for (int i = 0; i < list.size(); i++) {
int cnt = map.get(list.get(i));
while (cnt > 0) {
arr[idx++] = list.get(i);
cnt--;
}
}
}
}
셸 정렬 (Shell's Sort)
삽입 정렬이 거의 정렬된 배열에서 최적의 성능을 내는 것에서 착안한 정렬 방법입니다.
삽입 정렬의 경우, 오름차순 정렬 기준, 내림차순으로 구성된 데이터에 대해서는 앞의 데이터와 하나씩 비교하며 모두를 교환해야되기 때문에 성능이 좋지 않습니다.
이러한 문제를 해결하기 위해 어느 정도 간격(gap)을 두어 삽입 정렬을 하는 것이 셸 정렬입니다.
간격 설정에 따라 시간 복잡도가 달라지므로 간격을 잘 선택해야 합니다.
간격 설정은 아래를 참고하면 됩니다. 절대적인 것은 아니고 많은 사람들이 경험상 빨랐던 간격을 정리해둔 것 입니다.
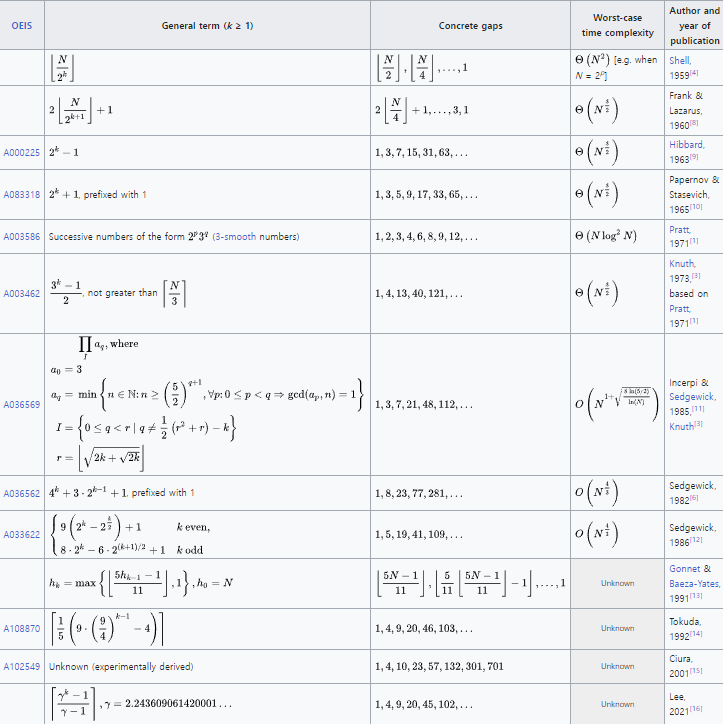
셸 정렬은 안정 정렬 입니다.
public class Shell {
public static void sort(int[] arr) {
/**
* gap sequence를 사용해도 됩니다. 정렬하려는 크기가 sequence의 범위를 넘어선다면, 2.25씩 계속 곱해서 늘리시면 됩니다.
* 여기서는 간단하게 배열의 절반으로 설정해두었습니다.
*/
int gap = arr.length / 2;
for (int g = gap; g > 0; g /= 2) {
for (int i = g; i < arr.length ; i++) {
// 삽입 정렬
int tmp = arr[i];
int j = 0;
for (j = i - g; j >= 0; j -= g) {
if (arr[j] > tmp) {
arr[j + g] = arr[j];
} else {
break;
}
}
arr[j + g] = tmp;
}
}
}
}
정렬 별 시간복잡도
기본적인 정렬 알고리즘들의 시간 복잡도는 다음과 같습니다.

추가적으로 여러 정렬 알고리즘을 섞은 하이브리드 정렬들이 있는데, 주로 사용하는 정렬로는 Tim Sort가 있습니다.
이 알고리즘 같은 경우엔 기본적인 정렬 알고리즘은 아니라서 본 설명에서는 제외했습니다.
'알고리즘 > 알고리즘' 카테고리의 다른 글
| 알고리즘 - 소수 구하기 (0) | 2023.05.24 |
|---|---|
| 알고리즘 - 최단 경로 알고리즘 (0) | 2023.05.23 |
| 알고리즘 - Union-Find (0) | 2023.05.10 |
| 알고리즘 - 최소 비용 신장 트리 (MST) (0) | 2023.05.10 |
| 알고리즘 - 배낭 문제 (Knapsack Problem) (0) | 2023.05.02 |
Contents
소중한 공감 감사합니다